Recursion vs. Iteration : Round 1
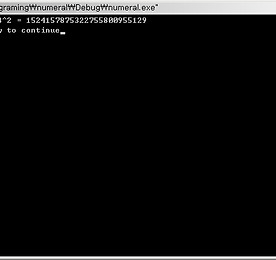
부제 : 그대, 피보나치 수열이라고 들어보았는가? Fibonacci Numbers Consider the following sequence of numbers, which begins with two 1's and where each successive term is equal to the sum of the preceding pair of terms. These numbers, called Fibonacci numbers, are arranged in the Fibonacci sequence 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, ... . If F1 = 1, F2 = 1, F3 = 2, F4 = 3, and so on, then this sequence can b..
더보기
Recursion vs. Iteration : Round 1
부제 : 그대, 피보나치 수열이라고 들어보았는가? Fibonacci Numbers Consider the following sequence of numbers, which begins with two 1's and where each successive term is equal to the sum of the preceding pair of terms. These numbers, called Fibonacci numbers, are arranged in the Fibonacci sequence 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, ... . If F1 = 1, F2 = 1, F3 = 2, F4 = 3, and so on, then this sequence can b..
더보기